
Recognizing the Value of Custom Web Crawlers

When it comes to data extraction, many organizations often turn to generic web scraping tools, believing they will meet all their needs. However, these tools can fall short when faced with the complexities of unique data structures and ever-evolving web environments.
Imagine trying to fit a square peg into a round hole. That’s what using a one-size-fits-all scraping tool feels like when your business has specific requirements. Generic tools may handle basic tasks efficiently, but they often struggle with dynamic websites, sites that require login credentials, or content hidden behind JavaScript. This is where custom web crawlers come into play.
Custom solutions are designed specifically for your business needs. They can adapt to the unique architecture of your target websites and efficiently navigate any changes in layout or structure. For example, if your competitors frequently update their pricing or product listings, a custom crawler can be programmed to monitor these changes in real-time, ensuring you always have the most current data at your fingertips.
Moreover, with the rise of anti-scraping measures, generic tools may struggle to bypass these barriers. A tailored solution can incorporate advanced techniques to mimic human behavior, reducing the risk of being blocked and ensuring a steady flow of valuable data.
Ultimately, investing in custom web crawling solutions not only enhances your data extraction capabilities but also drives operational efficiency and profitability. By addressing the specific challenges your business faces, you empower your team with the insights needed to make informed decisions.
Crafting an Effective Web Crawling Solution
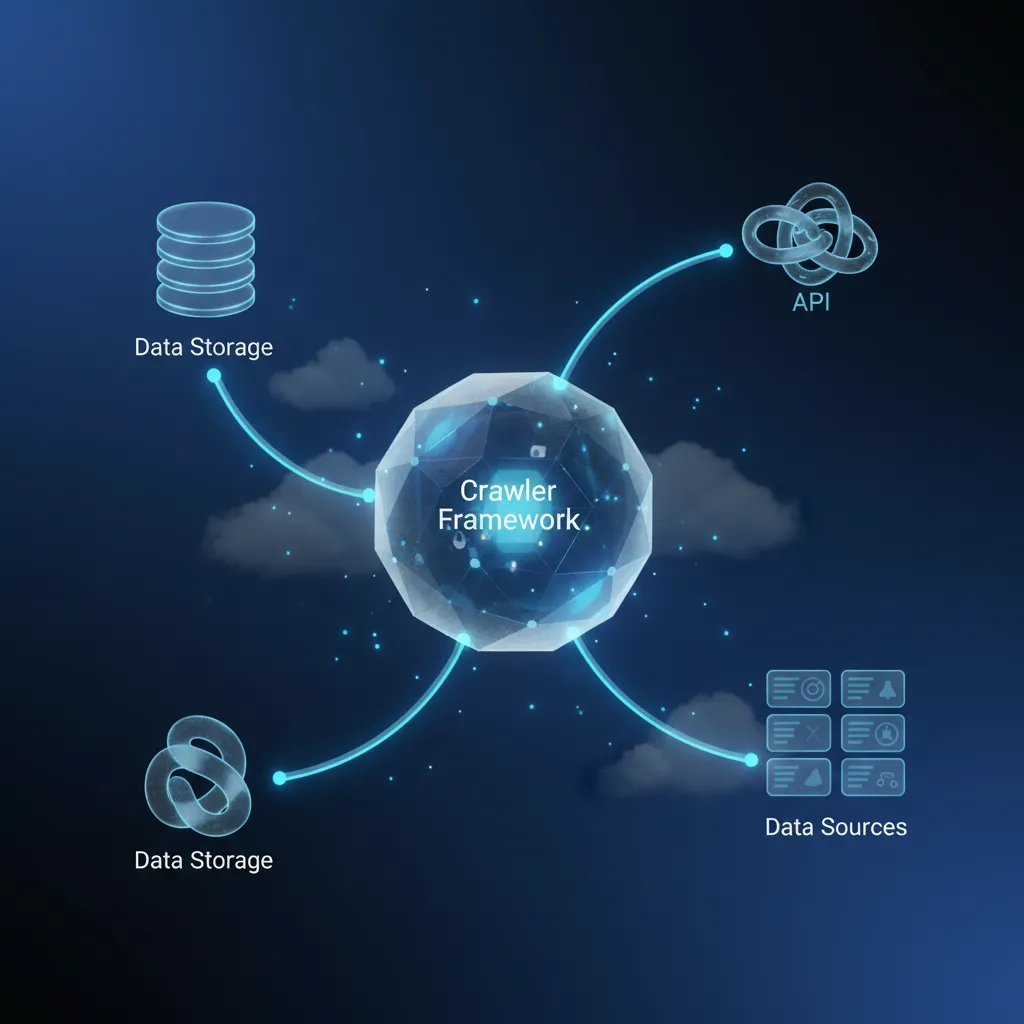
When it comes to designing a web crawling solution, it’s essential to focus on a few key elements that can make or break your project. Let’s dive into the architecture of a custom web crawler, highlighting the critical components that contribute to its success.
At the heart of any web crawler lies the crawler framework. This framework is where the magic begins. It determines how efficiently your crawler navigates the web, processes data, and stores it for future use. A well-structured framework allows your crawler to handle various types of websites and adapt to changes in their structure, ensuring you capture the right data consistently.
Next, let’s talk about data storage solutions. Depending on your data volume and usage, you’ll want to choose a storage method that balances speed and accessibility. Options range from traditional relational databases to more scalable NoSQL databases. The right choice here will enable quick data retrieval and efficient data processing, which is vital for making timely business decisions.
Integrating APIs can further enhance your web crawling capabilities. APIs allow your crawler to interact with external platforms seamlessly, pulling in additional data or pushing processed information back to your systems. This integration can streamline workflows and ensure that your data stays relevant and up-to-date.
While designing your web crawling solution, don’t overlook the importance of scalability and performance. As your data needs grow, your crawler must be able to scale without compromising speed or efficiency. By implementing a robust architecture that supports parallel processing and load balancing, you can ensure that your operations remain smooth even as demand increases.
Finally, consider the data processing capabilities of your solution. Efficient data processing not only saves time but also enhances the quality of insights you can derive from your data. By incorporating advanced parsing techniques and leveraging machine learning algorithms, you can transform raw data into valuable information that drives strategic decisions.
Enhancing Scalability and Performance with Custom Web Crawlers

As your data extraction needs grow, ensuring your web crawling solution can scale efficiently becomes paramount. A custom web crawler is not just a tool; it’s a strategic asset that should evolve alongside your business demands. Let’s explore how you can achieve this.
First, consider load balancing. When multiple requests are made to a website, distributing these requests evenly across different servers prevents any single server from becoming overwhelmed. This ensures your crawler operates smoothly, even during peak times. By implementing a load balancer, you can direct traffic intelligently, optimizing resource utilization and enhancing the overall performance of your crawling operations.
Another effective strategy is distributed crawling. This involves breaking down the crawling task into smaller, manageable segments that can be processed simultaneously across multiple machines. Imagine a team of workers tackling a large project together, each focused on a specific aspect. This parallel processing not only speeds up data extraction but also allows for greater resilience against website rate limits and blocks.
Lastly, optimizing crawling speed without sacrificing data quality is crucial. Implementing intelligent algorithms that prioritize essential data while adhering to polite crawling practices can significantly enhance your crawler’s efficiency. Using techniques such as adaptive crawling—where the crawler learns and adjusts its strategy based on previous performance—ensures that you gather the most valuable data quickly and accurately.
By focusing on scalability and performance, you can transform your web crawling solution into a powerful engine that drives business insights and decision-making.
Optimizing Cost-Efficiency and Budgeting for Custom Web Crawling Solutions

When it comes to developing a custom web crawler, understanding the cost implications is crucial for effective budgeting. Several factors come into play that can significantly influence the overall project pricing.
- Complexity: The more intricate your requirements, the higher the development cost. A simple scraper may suffice for basic data extraction, but if you need advanced features like handling CAPTCHAs or integrating with APIs, the complexity—and thus the cost—escalates.
- Data Volume: The amount of data you intend to scrape also impacts pricing. Larger datasets require more robust infrastructure and processing power, which can increase both initial setup costs and ongoing operational expenses.
- Ongoing Maintenance: Custom solutions require regular updates and maintenance to adapt to changes in target websites and evolving business needs. This ongoing support should be factored into your budget to avoid surprises down the line.
To help you estimate project pricing and ROI, consider this framework:
- Identify your specific requirements: List the features and functionalities that are non-negotiable.
- Assess the data volume: Estimate how much data you need and how often it will be scraped.
- Evaluate maintenance needs: Determine how often updates will be required and factor in the costs of ongoing support.
- Calculate expected ROI: Think about how the data will drive business decisions or operational efficiency, and weigh this against your total investment.
By taking a structured approach to budgeting, you can ensure that your investment in a custom web crawler is not only cost-effective but also aligned with your overarching business goals.
Achieving Unmatched Data Accuracy and Quality

When it comes to web scraping, the challenges surrounding data accuracy and data quality can feel overwhelming. You may find yourself sifting through vast amounts of information, only to realize that much of it is flawed or outdated. This is where the importance of implementing robust data validation checks and cleansing processes comes into play.
Imagine you’re running a business that relies on competitive pricing data to make informed decisions. If your web scraper pulls in inaccurate or inconsistent data, it can lead to misguided strategies and lost revenue. The consequences of poor data quality can be detrimental, affecting everything from customer satisfaction to operational efficiency.
This is why investing in custom web crawlers is essential. Unlike generic scraping tools, custom solutions are designed with your specific needs in mind. They can integrate validation checks that assess the integrity of the data as it’s being collected. For example, a custom crawler can cross-reference data against reliable sources, ensuring that the information you receive is not only accurate but also relevant.
Moreover, implementing data cleansing processes can significantly enhance the quality of your output. By identifying and correcting inaccuracies, removing duplicates, and standardizing formats, you can transform raw data into actionable insights. This not only saves time but also empowers you to make decisions grounded in reliable information.
Ultimately, by prioritizing data accuracy and quality through tailored web scraping solutions, you can unlock the full potential of your data, making it a powerful asset for your organization.
Optimizing Your Data Delivery and Storage Solutions

When it comes to web scraping, the way you receive and store your data can significantly impact your operational efficiency. Clients often ask about the various formats available for data delivery, and I assure them that whether you prefer CSV, JSON, or direct database integration, we have tailored solutions to meet your needs.
CSV files are a popular choice due to their simplicity and ease of use. They can be effortlessly imported into spreadsheet applications, making them ideal for quick analyses. On the other hand, JSON is particularly useful for applications that rely on APIs, as it provides a structured way to exchange data. For businesses that require real-time data processing, we can set up direct integrations with your databases, allowing for seamless data flow.
Storage solutions are equally critical. Depending on your operational requirements, you might opt for cloud storage, which offers flexibility and scalability. Services like AWS or Google Cloud can provide you with robust storage options that grow with your business. Alternatively, if data security and control are paramount, an on-premise database might be the right fit. This setup ensures that sensitive information remains within your infrastructure.
Moreover, once your data is stored, visualization tools can transform raw data into actionable insights. Tools like Tableau or Power BI allow you to create dynamic reports, enabling you to make informed decisions swiftly.
Ultimately, the choice of data format and storage solution should align with your business goals, ensuring that you can leverage the power of data scraping to enhance your operational capabilities.
Conquering the Hurdles of Web Scraping

As you delve into the world of web scraping, you’ll likely encounter a few obstacles that can hinder your progress. I’ve seen these challenges firsthand, and understanding how to navigate them is crucial for any effective web crawling strategy. Let’s explore some common issues and how to overcome them.
- IP Blocking: Many websites implement measures to prevent scraping, and one of the most prevalent is IP blocking. When your requests come too frequently from the same IP address, the site may flag you as a bot. To counter this, consider using rotating proxies or a pool of IP addresses. This way, you can distribute your requests across different IPs, mimicking organic user behavior.
- CAPTCHA: Another common roadblock is CAPTCHA, designed to differentiate between human users and bots. To tackle this, you can utilize CAPTCHA-solving services or machine learning algorithms that can learn to bypass these challenges. However, be cautious about ethical implications and ensure compliance with the website’s terms of service.
- Dynamic Content: With the rise of JavaScript-heavy websites, scraping static HTML can sometimes feel like trying to catch smoke with your bare hands. To effectively extract data from these sites, use headless browsers or tools that can render JavaScript. This approach allows you to interact with the content just as a user would, ensuring you capture all necessary information.
By implementing these strategies, you can significantly enhance your web scraping efforts. Remember, the goal is not just to scrape data but to do so in a way that is efficient, ethical, and sustainable. With the right tools and techniques, you can transform these challenges into stepping stones for success.
Frequently asked questions
Why are generic web scraping tools often insufficient for complex data extraction needs?
Generic tools struggle with dynamic websites, sites requiring login credentials, or content hidden behind JavaScript, making them unsuitable for unique data structures and evolving web environments.
How can web scraping solutions effectively bypass anti-scraping measures?
Tailored solutions can incorporate advanced techniques to mimic human behavior, reducing the risk of being blocked and ensuring a steady flow of valuable data.
What are the consequences of poor data quality in web scraping, and how can it be improved?
Poor data quality can lead to misguided strategies, lost revenue, and affect customer satisfaction and operational efficiency. Implementing robust data validation checks and cleansing processes can significantly enhance data quality.
How can web crawling solutions be scaled to handle growing data extraction demands?
Scalability can be achieved through load balancing, distributing crawling tasks across multiple machines (distributed crawling), and optimizing crawling speed with intelligent algorithms like adaptive crawling.
What factors influence the cost of developing a custom web crawling solution?
The cost is influenced by the complexity of requirements, the volume of data to be scraped, and the need for ongoing maintenance and updates.
How can DataFlirt’s custom web crawling solutions enhance data extraction capabilities and profitability?
DataFlirt’s custom web crawling solutions are designed to adapt to unique website architectures and bypass anti-scraping measures, ensuring you get current, accurate data to drive operational efficiency and profitability.
What types of data delivery and storage solutions does DataFlirt offer for web scraped data?
DataFlirt offers flexible data delivery in formats like CSV and JSON, or direct database integration. For storage, we provide options including scalable cloud storage (AWS, Google Cloud) or secure on-premise databases.
How does DataFlirt ensure data accuracy and quality in its tailored web scraping solutions?
DataFlirt integrates robust data validation checks during collection and implements comprehensive data cleansing processes to identify and correct inaccuracies, remove duplicates, and standardize formats, transforming raw data into actionable insights.


