How To Convert Websites Into Apis With Web Scraping

Embracing the Power of APIs for Seamless Data Access

As I navigate the evolving digital landscape, one thing becomes clear: the demand for APIs is skyrocketing across various sectors. Whether you’re in finance, e-commerce, or healthcare, the ability to access and integrate data seamlessly has become a cornerstone of operational efficiency.
APIs, or Application Programming Interfaces, serve as bridges that allow different software systems to communicate with each other. They enable organizations to pull data from a variety of sources, making it easier to innovate and respond to market demands. However, traditional methods of data access often come with significant limitations. These methods can be time-consuming, require extensive manual effort, and may not provide real-time data. This is where web scraping comes into play.
Web scraping allows you to extract valuable data from existing websites, transforming it into structured formats that can be easily integrated into your systems. By leveraging web scraping, you can create custom APIs tailored to your specific needs, facilitating quicker access to essential data without the constraints of traditional data sources. Imagine being able to gather competitive pricing data from numerous e-commerce sites effortlessly or aggregating customer reviews from multiple platforms for insights in real-time.
The advantages of using web scraping to create APIs are clear: enhanced data access, reduced operational costs, and improved decision-making capabilities. In a world where timely information is crucial, using web scraping to harness the power of APIs can be a game-changer for your business. It’s not just about collecting data; it’s about transforming that data into actionable insights that drive your digital transformation.
Choosing the Right Websites for API Conversion

When it comes to converting websites into APIs, the first step is identifying the right target websites. This process is crucial as not every website is suitable for conversion. Here are some key criteria to consider.
- Data Availability: The primary factor to look at is the availability of data. You want to ensure that the website you’re targeting has rich and structured data that can be extracted easily. For instance, e-commerce platforms with product listings, prices, and reviews offer a treasure trove of information that can be converted into a functional API.
- Website Structure: A well-structured website, with clear navigation and consistent HTML tags, makes the scraping process smoother. Websites that employ simple layouts or APIs for their own data serve as ideal candidates. For example, news aggregators that categorize articles by topics can provide valuable data for media analysis.
- Legal Considerations: Before diving in, it’s essential to understand the legal landscape surrounding web scraping. Ensure you review the website’s terms of service and check for any restrictions on data usage. Industries like finance, where compliance is critical, must tread carefully to avoid legal pitfalls.
Several industries can significantly benefit from converting websites into APIs. For example, travel agencies can pull in data from multiple airlines and hotels to offer comprehensive booking solutions. Similarly, market research firms can aggregate data from various sources to enhance their analytics capabilities.
By carefully selecting your target websites based on these criteria, you can unlock valuable data that drives operational efficiency and informed decision-making.
Unveiling the Web Scraping Process for Effective API Development
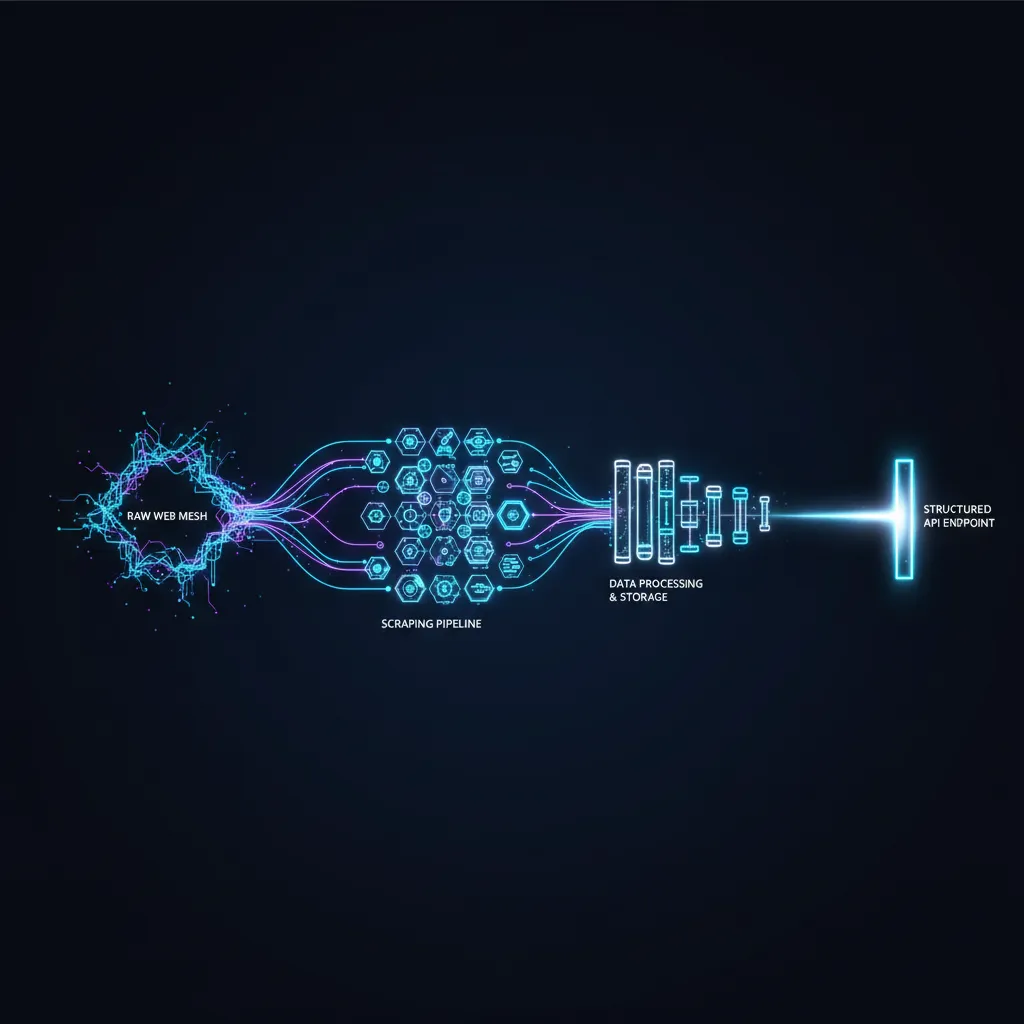
When it comes to leveraging data from the web, the web scraping process is a crucial foundation for creating robust APIs. Let’s break down this process into manageable steps that can transform raw web data into structured information.
1. Planning
The first step in any web scraping project is planning. Start by identifying the specific data you need and the websites from which you intend to scrape. Understanding the target website’s structure is essential. Tools like XPath or CSS selectors can help you navigate through the HTML layout effectively. Consider any legal implications or terms of service that the site may have, ensuring your approach aligns with ethical scraping practices.
2. Scraping
Once you have a clear plan, it’s time to dive into the scraping phase. Utilizing Python along with frameworks like Scrapy or Beautiful Soup can significantly streamline this process. These tools allow you to write scripts that can extract data efficiently. For instance, Scrapy is particularly powerful for handling large volumes of data and can manage multiple requests simultaneously, making it a favorite among developers.
3. Data Cleansing
After scraping, the next step is data cleansing. Raw data often comes with inconsistencies and irrelevant information. Tools such as Pandas in Python can help you clean and organize your data. This might involve removing duplicates, handling missing values, or converting data types. The goal here is to ensure that your data is accurate and ready for use.
4. API Development
The final step is to transform your cleaned data into an accessible format via an API. Using RESTful services, you can create endpoints that allow other applications to interact with your data seamlessly. Frameworks like Flask or Django can assist in building these APIs quickly. Make sure to define clear documentation for your API, which is essential for developers who will be consuming your data.
By following these steps, you can effectively harness the power of web scraping to create APIs that provide valuable insights and drive better decision-making in your organization. Remember, the right tools and technologies can make all the difference in streamlining this process and ensuring the success of your data-driven initiatives.
Overcoming Web Scraping Challenges: Practical Solutions
When you delve into the world of web scraping, it’s easy to be captivated by the potential of extracting valuable data. However, as you embark on this journey, you’ll likely encounter various scraping challenges that can hinder your efforts. Let’s explore some common obstacles and practical solutions to navigate them effectively.
1. Anti-Scraping Measures
Many websites employ anti-scraping measures to protect their data. These can include IP blocking, CAPTCHAs, and rate limiting. Imagine trying to enter a locked door repeatedly; eventually, you’ll be asked to leave. To combat this, consider using rotating proxies to change your IP address frequently. This approach allows you to distribute your requests across multiple addresses, reducing the likelihood of being blocked.
2. Data Quality Issues
Another significant challenge in web scraping is ensuring data quality. Inconsistent formats, incomplete data, or even incorrect information can lead to flawed analyses. To maintain high data quality, implement validation checks during your scraping process. For instance, if you’re scraping product prices, ensure that the data you collect is numeric and falls within a reasonable range. Regularly audit your data and apply cleaning techniques to rectify any inconsistencies.
3. Website Changes
Websites are dynamic; they often change their structure or layout, which can break your scraping scripts. Picture trying to follow a recipe that keeps changing every time you glance away. To mitigate this issue, build your scraping solutions with flexibility in mind. Utilize tools that allow you to easily adjust your scripts when websites undergo changes. Additionally, set up alerts to notify you of any discrepancies in the data you’re collecting, so you can quickly address issues as they arise.
Best Practices for Effective Web Scraping
- Respect Robots.txt: Always check the website’s robots.txt file to understand the scraping rules.
- Throttle Your Requests: Avoid overwhelming servers by pacing your requests.
- Use Headless Browsers: Tools like Puppeteer or Selenium can simulate human browsing behavior, making it harder for anti-scraping measures to detect your activity.
By recognizing these challenges and employing effective strategies, you can enhance your web scraping efforts, ensuring that you extract valuable insights while navigating the complexities of the digital landscape.
Enhancing Scalability and Performance in Web Scraping Solutions

When it comes to managing a growing demand for data, scalability is a fundamental aspect of any web scraping solution. As your business evolves and data needs expand, having a framework that can adapt is essential. You might think of it like a well-crafted recipe—each ingredient must be measured precisely, but the recipe should allow for adjustments based on the number of servings you need.
To achieve scalability in web scraping, consider using cloud-based infrastructures that can dynamically allocate resources based on your current requirements. This approach not only enhances performance but also ensures that you only pay for what you use, making it incredibly cost-effective. For instance, if you’re scraping a small dataset today but anticipate a surge in data extraction tomorrow, cloud solutions can ramp up the necessary computing power without a hitch.
Performance metrics are crucial in assessing the efficiency of your web scraping efforts. Key indicators include:
- Data Extraction Speed: How quickly can you gather the information you need?
- Accuracy: Is the data collected reliable and free from errors?
- Resource Utilization: Are you maximizing your infrastructure to get the best results?
Implementing strategies like parallel processing and load balancing can significantly improve your scraping performance. By distributing tasks across multiple servers, you can extract vast amounts of data in a fraction of the time without compromising on quality.
Ultimately, the ROI of a well-structured web scraping solution can be substantial. By optimizing for scalability and performance, you ensure your business remains agile and responsive to market demands, paving the way for informed decision-making and enhanced operational efficiency.
Efficient Data Delivery: Formats and Storage Solutions

When it comes to delivering scraped data to clients, choosing the right formats and storage solutions is crucial for effective utilization. Over the years, I’ve seen how different formats can impact the way clients access and analyze their data.
Let’s start with the formats. JSON (JavaScript Object Notation) is a popular choice due to its lightweight nature and ease of use with web applications. It allows for structured data representation, making it ideal for developers who need quick access to data. On the other hand, XML (eXtensible Markup Language) offers a more verbose structure, which can be beneficial when data needs to be self-descriptive or when integrating with legacy systems. Finally, CSV (Comma-Separated Values) is favored for its simplicity and compatibility with spreadsheet applications. It’s an excellent choice when clients need to perform quick analyses or visualize data using tools like Excel.
Now, let’s talk about storage solutions. For relational data, SQL (Structured Query Language) databases are a reliable option. They provide structured storage and are great for complex queries. However, when dealing with large volumes of unstructured data, NoSQL databases shine. They allow for flexible data models and can scale horizontally, accommodating the ever-growing data needs of businesses.
Ultimately, how clients access and utilize this data depends on their specific requirements. APIs can be set up for real-time data retrieval, while regular data dumps can be scheduled for periodic updates. By understanding these formats and storage options, you can make informed decisions that enhance your operational efficiency and decision-making capabilities.
Transformative Case Studies: Real-World Applications of Web Scraping

When it comes to harnessing the power of data, web scraping has emerged as a game-changer for many organizations. Let’s explore a couple of compelling case studies that highlight how businesses have successfully converted websites into APIs, demonstrating significant impacts on their operations, efficiency, and decision-making processes.
One standout example is a leading e-commerce retailer that faced challenges in monitoring competitor pricing. By implementing a web scraping solution, they were able to extract real-time pricing data from competitor websites. This information was then transformed into a dynamic API that fed directly into their pricing strategy software. The result? They achieved a remarkable 20% increase in sales within the first quarter due to timely adjustments in their pricing model, allowing them to stay competitive and responsive to market changes.
Another inspiring success story comes from a financial services firm. They needed to gather vast amounts of data from multiple financial news websites to inform their investment strategies. By creating an automated web scraping tool, they transformed these websites into a centralized API that aggregated news articles and market analysis. This solution not only streamlined their data collection process but also reduced the time analysts spent on research by 30%. Consequently, their decision-making became faster and more data-driven, significantly enhancing their investment accuracy.
These case studies illustrate just how impactful web scraping can be. By converting websites into APIs, organizations can unlock valuable insights, improve operational efficiency, and make informed decisions that drive success.
Frequently asked questions
How can businesses access real-time data from various online sources efficiently?
Businesses can leverage web scraping to extract valuable data from existing websites, transforming it into structured formats. This data can then be integrated into custom APIs, providing quicker and more efficient access to essential information without the limitations of traditional data sources.
What are the common challenges encountered when trying to extract data from websites?
Common challenges include anti-scraping measures like IP blocking and CAPTCHAs, ensuring high data quality amidst inconsistencies, and adapting to frequent website structure changes that can break scraping scripts.
How can one ensure the quality and consistency of data obtained through web scraping?
To ensure data quality, implement validation checks during the scraping process, regularly audit collected data, and apply cleansing techniques to remove duplicates, handle missing values, and convert data types for accuracy and consistency.
What are the legal considerations to keep in mind before scraping data from a website?
Before scraping, it’s crucial to review the website’s terms of service and check for any restrictions on data usage. Adhering to ethical scraping practices and understanding the legal landscape, especially in compliance-critical industries like finance, is essential to avoid legal pitfalls.
How can web scraping solutions be scaled to meet growing data demands?
Scalability can be achieved by using cloud-based infrastructures that dynamically allocate resources. Implementing strategies like parallel processing and load balancing can distribute tasks across multiple servers, allowing for efficient extraction of vast amounts of data as needs expand.
How can DataFlirt help my business convert websites into custom APIs for seamless data access?
DataFlirt specializes in transforming raw web data into structured information and developing robust APIs. We can help you plan, scrape, cleanse, and develop custom APIs tailored to your specific needs, ensuring seamless data access and integration for your business.
What kind of support does DataFlirt offer for overcoming web scraping challenges like anti-scraping measures?
DataFlirt provides expert solutions to overcome web scraping challenges, including implementing rotating proxies to bypass IP blocking, advanced data validation and cleansing techniques for quality assurance, and flexible scraping solutions designed to adapt to website changes.
Can DataFlirt provide tailored web scraping solutions to enhance my business’s operational efficiency and decision-making?
Yes, DataFlirt offers customized web scraping services designed to unlock valuable insights, improve operational efficiency, and drive informed decision-making. Our solutions are built for scalability and performance, ensuring your business remains agile and responsive to market demands.

Nishant Choudhary
https://dataflirt.com/I'm a web scraping consultant & python developer. I love extracting data from complex websites at scale.