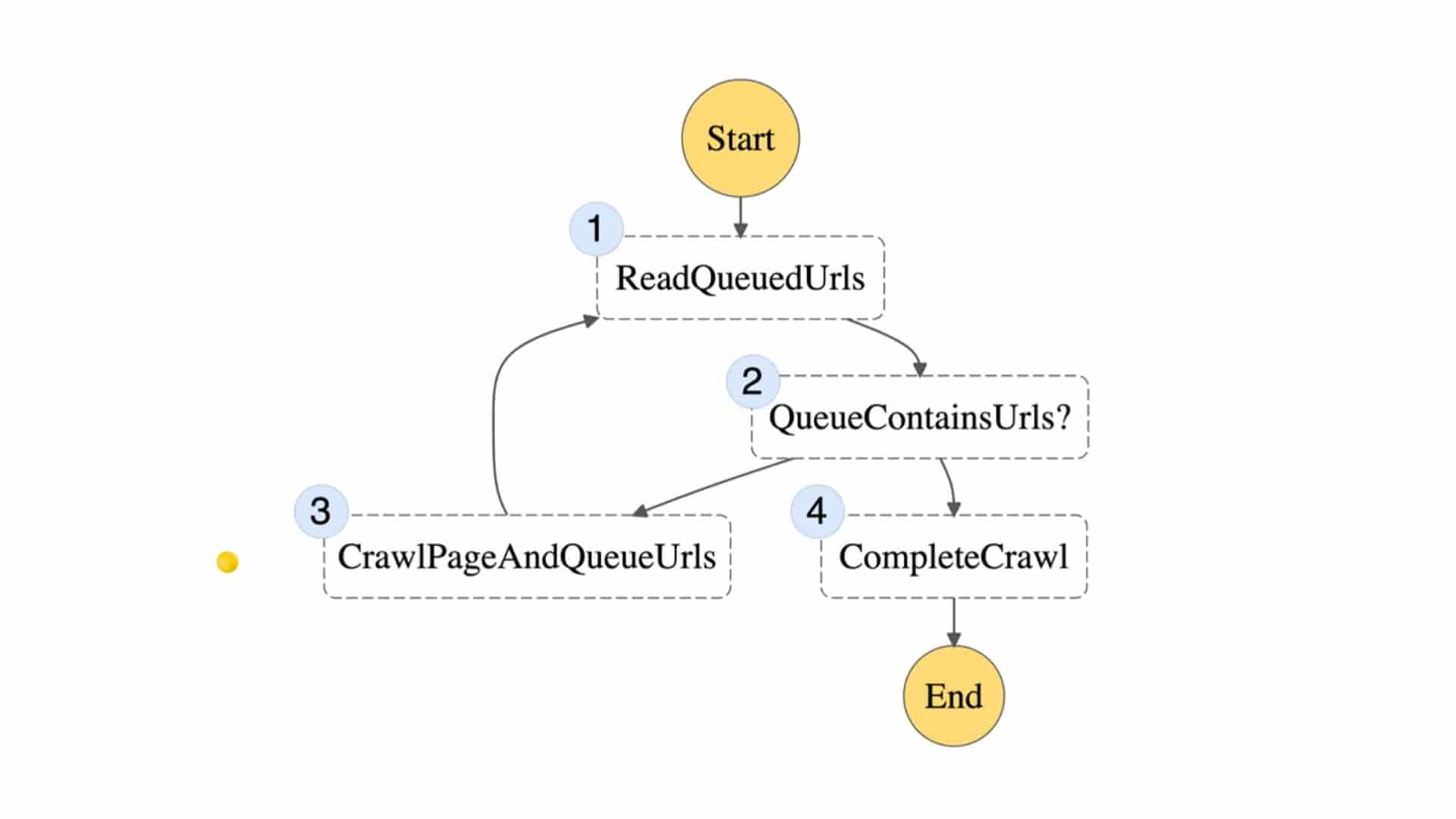
Grasping the Essentials of the Web Data Acquisition Framework

The web data acquisition framework serves as a structured blueprint for efficiently gathering and processing data from online sources. At its core, this framework consists of several key components: data sources, extraction methods, and data processing techniques. Understanding these elements is crucial for anyone looking to leverage web scraping for strategic advantage.
Data sources represent the wellspring of information you aim to extract. They can range from e-commerce sites and social media platforms to news outlets and industry-specific databases. Identifying the right data sources ensures that you’re capturing relevant information that aligns with your business objectives.
Once the data sources are established, the next step involves choosing appropriate extraction methods. Techniques such as HTML parsing, APIs, and headless browsing are all viable options, each suited to different scenarios. Selecting the right method impacts not just the efficiency of data collection, but also the quality and accuracy of the data retrieved.
Finally, the data processing techniques you employ will determine how well you can transform raw data into actionable insights. This could involve cleaning the data, aggregating it, or applying analytical models to derive meaningful conclusions.
By adopting a structured approach through the web data acquisition framework, you pave the way for better decision-making. With reliable and timely data at your fingertips, you can enhance your data-driven strategies, respond to market changes swiftly, and ultimately drive your organization towards success. Whether you’re a project manager or a developer, understanding this framework is key to unlocking the full potential of web scraping in your business initiatives.
Unpacking the Essential Components of Effective Web Scraping

When we think about successful web scraping, it’s crucial to understand the key components that work in harmony to create a seamless data acquisition process. Each element, from data extraction tools to APIs and automation, plays a vital role in how we gather and utilize data from the web.
First, let’s talk about data extraction tools. These are the backbone of any web scraping initiative. They allow you to pull information from various web pages efficiently. Whether it’s a simple HTML parser or a more complex scraping framework, the effectiveness of these tools can significantly impact the quality and quantity of the data you collect. For example, using a tool like Scrapy can help you navigate through complex websites and extract structured data without getting bogged down by irrelevant information.
Next, we have APIs. While web scraping often involves extracting data from web pages, APIs can offer a more stable and reliable source of information. Many websites provide APIs that allow you to access their data in a structured format, which can save you time and effort. By leveraging APIs, you can often bypass the challenges of scraping dynamic content or dealing with website changes, ensuring that your data remains consistent and accurate.
Automation is another critical component of effective web scraping. The ability to automate data extraction not only speeds up the process but also reduces the potential for human error. Imagine having a script that runs at scheduled intervals to scrape the latest data from your target websites. This level of automation means you can focus on analyzing the data rather than spending hours on manual extraction.
When these components—data extraction tools, APIs, and automation—work together, they create a powerful framework for data acquisition. Think of it as a well-oiled machine; each part has its function, and when they operate in sync, the result is a streamlined process that maximizes efficiency and accuracy.
The implications of leveraging these components are profound. Not only does it enhance your data gathering capabilities, but it also empowers you to make data-driven decisions faster. Whether you’re a business analyst looking for market trends or a project manager needing insights for strategic planning, understanding and implementing these web scraping components can transform your approach to data.
Optimizing Scraping Solutions for Scalability and Performance

Scalability is not just a buzzword; it’s a critical aspect of any effective web scraping solution. As your data needs grow, your scraping architecture must evolve to handle increasing loads without compromising on performance. I’ve seen firsthand how businesses can falter when their scraping solutions aren’t built with scalability in mind.
When designing a robust scraping architecture, consider the cloud as a foundational element. Cloud solutions offer unparalleled flexibility, allowing you to scale resources up or down based on demand. This is especially useful during peak times when data extraction needs surge. For instance, a retail company I worked with leveraged cloud infrastructure to seamlessly accommodate spikes during holiday sales, ensuring they captured every valuable piece of data without missing a beat.
Another key component of scalability is load balancing. By distributing traffic evenly across multiple servers, you can prevent any single point of failure and maintain high performance. This approach not only enhances reliability but also optimizes resource utilization, which can lead to cost savings in the long run.
Additionally, distributed scraping techniques can greatly enhance your system’s ability to handle vast amounts of data. By breaking down tasks and distributing them across various nodes, you can scrape multiple pages simultaneously, significantly reducing the time taken to gather information. For example, a financial services client of mine used distributed scraping to gather real-time market data from numerous sources, allowing them to make informed decisions faster than competitors.
In summary, focusing on scalability and performance in your scraping solutions not only future-proofs your data strategy but also empowers your business to harness the full potential of web data.
Maximize Your ROI with Cost-Efficiency and Data Quality
cost-efficiency-and-data-quality.webp” alt=”maximize your roi with cost efficiency and data quality” width=”1364″ height=”966″ />
When it comes to web scraping, achieving cost-efficiency while ensuring data quality can feel like walking a tightrope. However, there are effective strategies that can help you maintain this delicate balance.
First, consider the scope of your project. Clearly defining your objectives upfront can prevent unnecessary expenses. For instance, if you need data for a specific market analysis, focus only on the relevant data sources. This targeted approach not only saves you time but also reduces costs significantly.
Next, invest in robust scraping tools and technologies. While it may seem counterintuitive to spend more initially, high-quality tools can automate processes and reduce manual labor. This ensures that you gather accurate data consistently, which is essential for informed decision-making. A case study I recall involved a client who transitioned from a basic scraping setup to a more advanced solution, resulting in a 40% reduction in data retrieval time and a noticeable improvement in data accuracy.
It’s also vital to implement a thorough validation process. Regularly checking the data for accuracy helps to maintain its quality. Creating a feedback loop where data is reviewed and refined can lead to insights that directly impact your bottom line.
Lastly, keep an eye on your budget management. Allocate resources wisely, balancing between what you need now and what might be required in the future. This approach not only enhances your ROI but also positions you to adapt to changing market demands without overspending.
By focusing on these strategies, you can ensure that your web scraping projects are not only financially sound but also provide the high-quality data essential for driving business success.
Overcoming Common Scraping Challenges
